

Python Code: Github Link
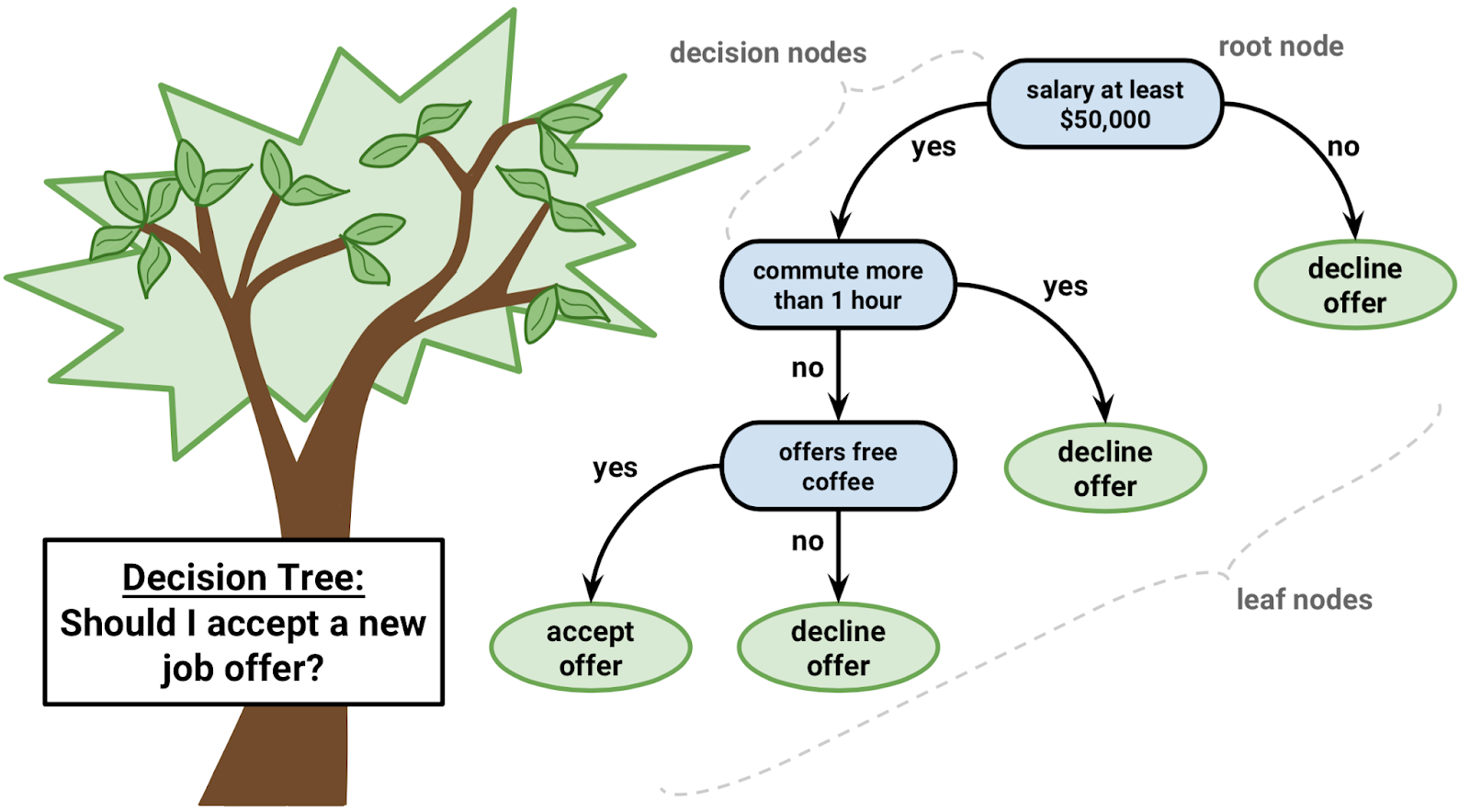
How Random Forest works? – It’s a forest of Trees!!
1. Simply, its a combination of many trees.
2. It’s always better to take more suggestions and decide on majority voting rather going for a single suggestion. Same principle works in our Random Forest.
3. In this way, the probability of error gets decreased.
4. So, it works similar to the decision tree.
5. The number of trees is the main parameter and remaining all similar to the decision tree.
How to know the optimal parameters where model performance is high?
1. Here comes the hyper-parameter tuning for increasing model performance.
2. There are two types of hyper-parameter tuning. i) Grid search and ii) Randomized search.
3. For both types, we have to give the ranges of parameters and algorithm searches in those ranges and gives us the optimal parameters.
4. Grid search searches in equal grids manner whereas randomized search searches randomly.
How our algorithm evaluates and gives optimal parameters?
1. This is where cross-validation comes into the picture.
2. Our algorithm divides the whole training set into k folds and trains the model with parameters on k-1 folds and test on the remaining 1 fold.
3. This gives us the accuracy of the model with the parameters. In this way, the algorithm evaluates and finds out the optimal parameters.

